
The Google URL removal tool was first launched in 2007 and has been in high demand since its inception. However, due to popular requests, the URL removal process was completed within 3 to 5 days. Since its inception, the processing time for Google URL removal requests has dropped dramatically. Now, when a site owner requests removing URLs from Google, the process results in less than 24 hours. Of course, this is if there is no emergency.
Google URL removal is not a one-time or permanent operation, as opposed to a well-known one. So even though the URL removal process works very fast, it doesn’t last forever. URL removal performed using the Search Console in accordance with Google’s rules will appear again in 90 days if done otherwise. In other words, the URL that you removed from Google today replaces the search results again after 90 days if no further action is taken.
How to Remove URLs?
There are several ways of removing URLs from Google. Each way have their own method. So, without further due, let’s take a look at them.
1. Delete content
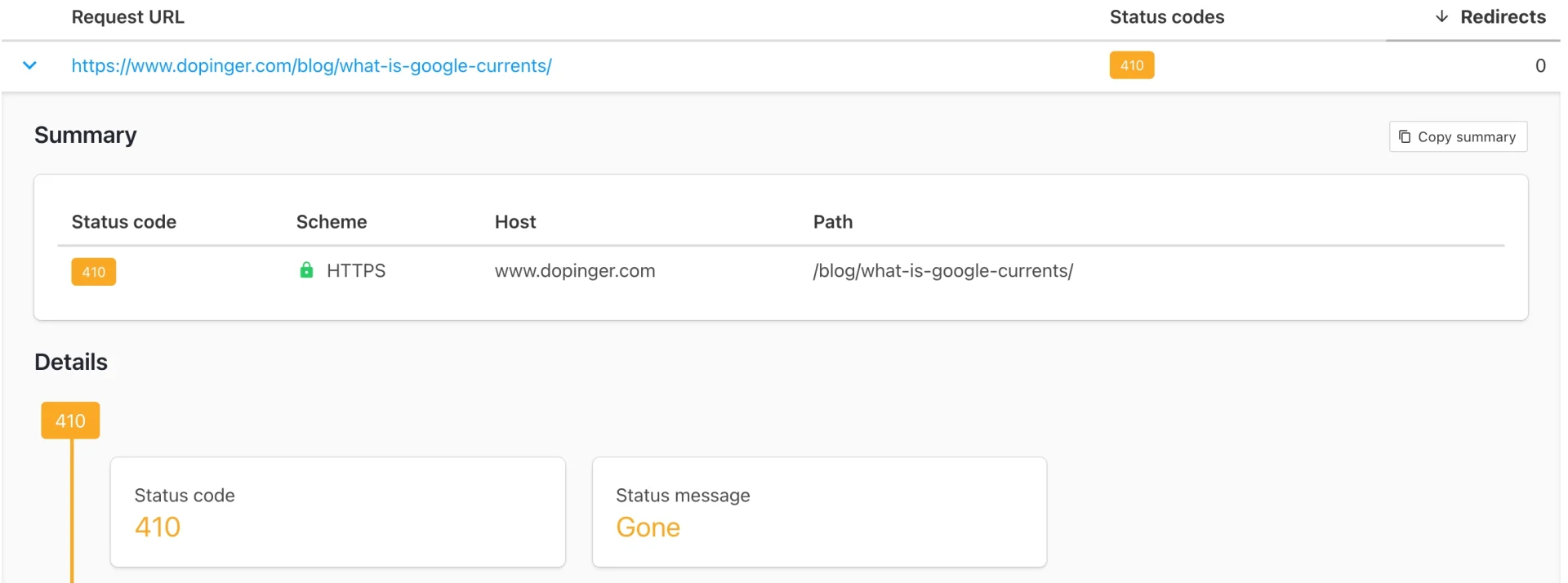
If you delete a page and present the 404 or 410 status code, the page is removed from the page index as soon as it is scanned again. The page may still appear in search results until it is deleted. You may temporarily use a cached version of the page, even if the page itself is no longer available.
2. Use the URL Removal Tool
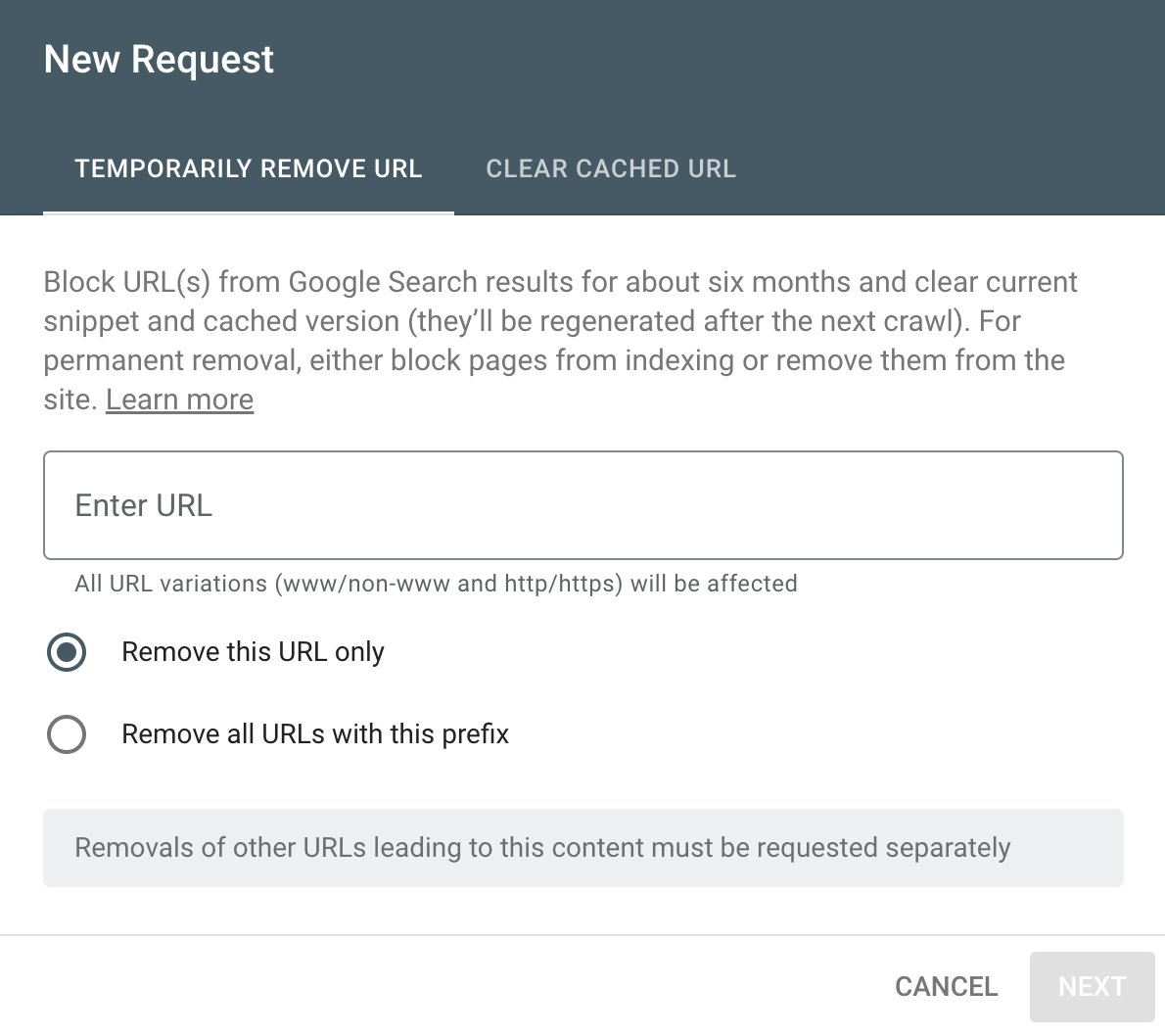
The name of this tool on Google is somewhat misleading because the way it works will temporarily hide your content. If you use this tool, google will continue to view and scan this content, but the pages will not be visible to users. This temporary effect lasts for six months at Google, and Bing has the same tool that lasts for three months. These tools include security issues, data leaks, individually identifiable information, etc. It should be used in extreme cases. Delete pages for a very long time if you have or link users to content. Also, blocking access to Google using the URL removal tool is the fastest way to hide pages. The request may take a day to process.
3. Restrict Access
If you do not want this page to be available to other users but search engines to access it, you may need to restrict access. The method you will use is to limit access to the authentication system. The Authentication system is a good practice used for things like testing, improving sites. When access is restricted using authentication systems, a group of users is allowed access to the page, but search engines cannot access and index pages.
4. Noindex
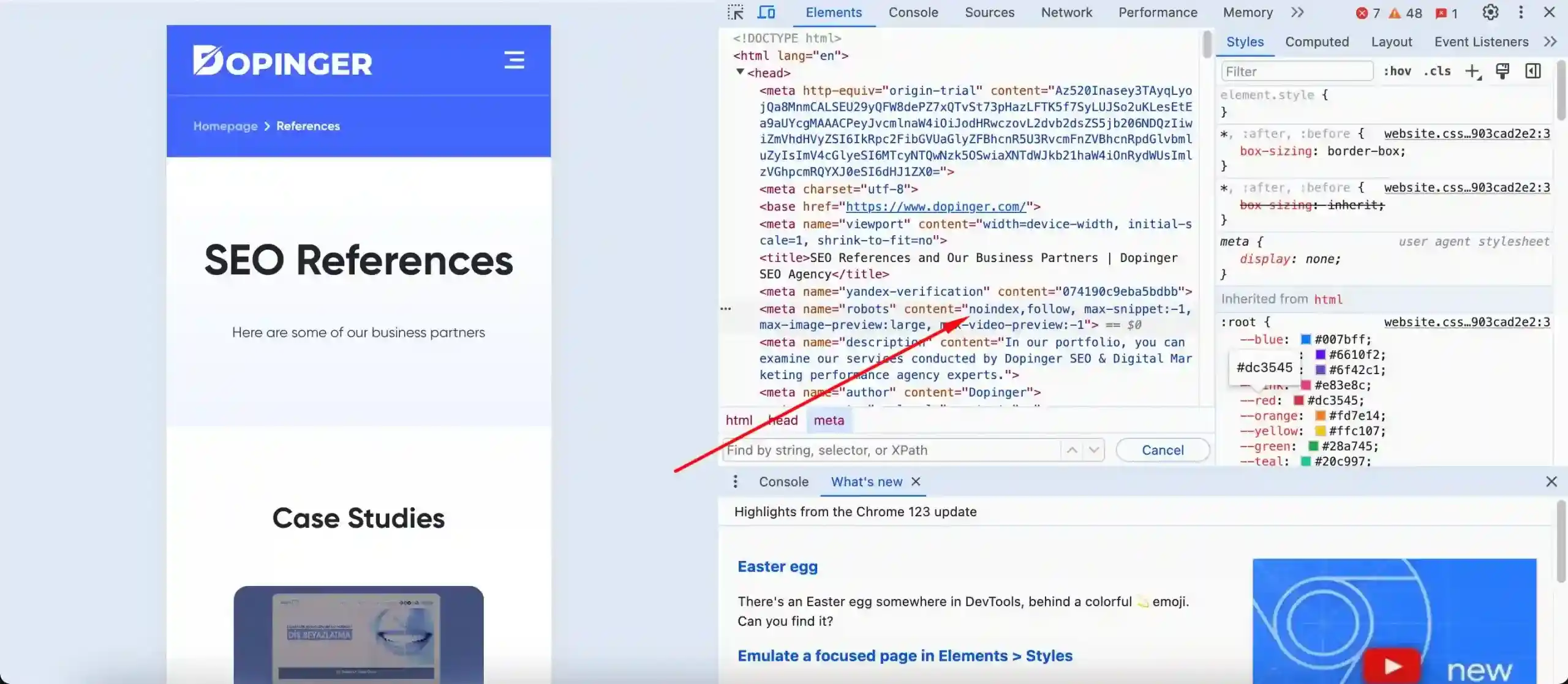
The noindex meta tag tells search engines to remove a page from the index. The Meta robots tag is intended to remove them from the Google directory for additional file types such as pages and PDFs. The search engine should be able to scan pages. It is to ensure that pages are not visible using this tag. So robots, instead of noindex make sure pages from the Txt file are not blocked. Robots.txt can create different errors, as it not only removes pages from the index but also prevents link scanning with other signals.
5. Canonicalization Planning
When you have multiple page versions and want to combine signals, such as links to a single version, you want to do the sorting process. This usually protects duplicate content when merging multiple page types into a single URL displayed.
You have many canonicalization options:
- Canonical Tag: This distinguishes it as the standard version or version you want to display. In other words, it specifies the version Google wants to scan as a different URL. If the pages are duplicated or almost identical, it is wise to use a canonical tag to solve them. This method may not work when pages are very different.
- Redirect: Redirect takes the user and the search bot from one page to another. The 301 redirect, which is most frequently used by search engine users also informs search engines that they want the last URL to link to the URL displayed in the search results. Temporary redirect tells search engines that the actual URL stays in the index and wants to redirect links from there to that URL.
- URL parameter management: The parameter is added at the end of the URL and usually contains a question mark, such as abcd.Com?this=parameter. Google Tool lets you tell URLs how to manage specific parameters. For example, you can specify whether the parameter changes the page content or just tracking usage.

Common Removal Errors to Avoid
Here are the common removal errors to avoid. Let’s take a look:
- Prevent crawling in Robots.txt file: Scanning is not the same as targeting. Even if Google pages are banned from scanning, it may still be an Index if there are internal or external links to the page. Google does not know what is on the page because it cannot scan the page, but it does know that the page exists, and it can type an A-title that will appear in search results by signals, such as link text if the page has links. So are robots. Instead of avoiding scanning the page using a Txt file, it is advisable to delete this page using noindex.
- Nofollow: This is often confused with noindex, and some people use it to ensure that the page is not displayed. Nofollow is a variety that specifies how a link is transmitted, and while it originally stopped scanning links on the page and individual links with the following attribute, this is no longer the case. Google can now scan those links if it wants to. Nofollow has been used on individual links to prevent Google from accessing certain pages, so it may be wise to use dofollow instead of this method, as google also scans non-existent links.
What Is a Canonical Tag?
As a website grows, it is often difficult to prevent the content of the pages from being duplicated or nearly identical with copies. This can cause “Duplicate Content” problems. If you have a few similar pages and are rated by a specific keyword for all pages, bots in the search engine will not know which URL to send traffic to. To resolve this, you need to report our favorite URL to Google in some way. In this case, the Canonical URL tag is activated.
As a result of access to the same content by search engines with two different link formats, it allows us to specify which link spiders will be based on the Rel Canonical tag. A common URL may appear by searching for a web page source. Standard URL refers to the URL of your choice. The Rel Canonical tag is something that only bots in a search engine can see. Your users will not be affected by it.
Conclusion About Removing URLs from Google
In this article, we have provided you with information about a few of the options where you can delete URLs and start using them right away by deciding which one is right for you. If you liked our article about removing URLs from Google, you may also like our article about how to submit a URL to Google.
Frequently Asked Questions About
First of all, the removal of a standard URL should be done with the Google Search Console. This will be done in less than 24 hours, and Google will remove the URL you want from its index within 90 days.
Log into Google Search Console and create an account. Click the URL button in the left-hand menu. Click the Request new button, and the cleaning process is complete.
Hiding URLs with sensitive content as a GSC removal tool is Google’s quick way to stop showing them in its SERPs. But remember that the tool only hides pages posted for 180 days, not removing them from the Google index. You can do this with the Search Console.
If you find that other websites are using your content, there are several ways to remove it from Google to resolve this situation. All you have to do is connect with the people who use the website. In many of these cases, when the “reader” copied your content by mistake, events become in the style of immediate action on the subject. You can offer them a link to you with a link including a canonical tag, redirect 301 to your URL, or delete it completely.
Robots of page-specific robots with indexing in Google Search. It is not recommended to use a Txt file, but Google recommends using it to delete indexed images.



 in Google Analytics: What Does It Mean?")
No comments to show.